Interrupt flow
Adapting the generic interrupt management (genirq)
Interrupt pipelining involves a basic change in controlling the
interrupt flow: handle_domain_irq() from the IRQ domain API
redirects all parent IRQs to the pipeline entry by calling
generic_pipeline_irq(), instead of generic_handle_irq().
Generic flow handlers acknowledge the incoming IRQ event in the
hardware as usual, by calling the appropriate irqchip routine
(e.g. irq_ack(), irq_eoi()) according to the interrupt
type. However, the flow handlers do not immediately invoke the in-band
interrupt handlers. Instead, they hand the event over to the pipeline
core by calling handle_oob_irq().
If an out-of-band handler exists for the interrupt received,
handle_oob_irq() invokes it immediately, after switching the
execution context to the oob stage if not current yet. Otherwise, the
event is marked as pending in the in-band stage’s log for the current
CPU.
The execution flow throughout the kernel code in Dovetail’s pipelined interrupt model is illustrated by the following figure. Note the two-step process: first we try delivering the incoming IRQ to any out-of-band handler if present, then we may play any IRQ pending in the current per-CPU log, among which non-OOB events may reside.
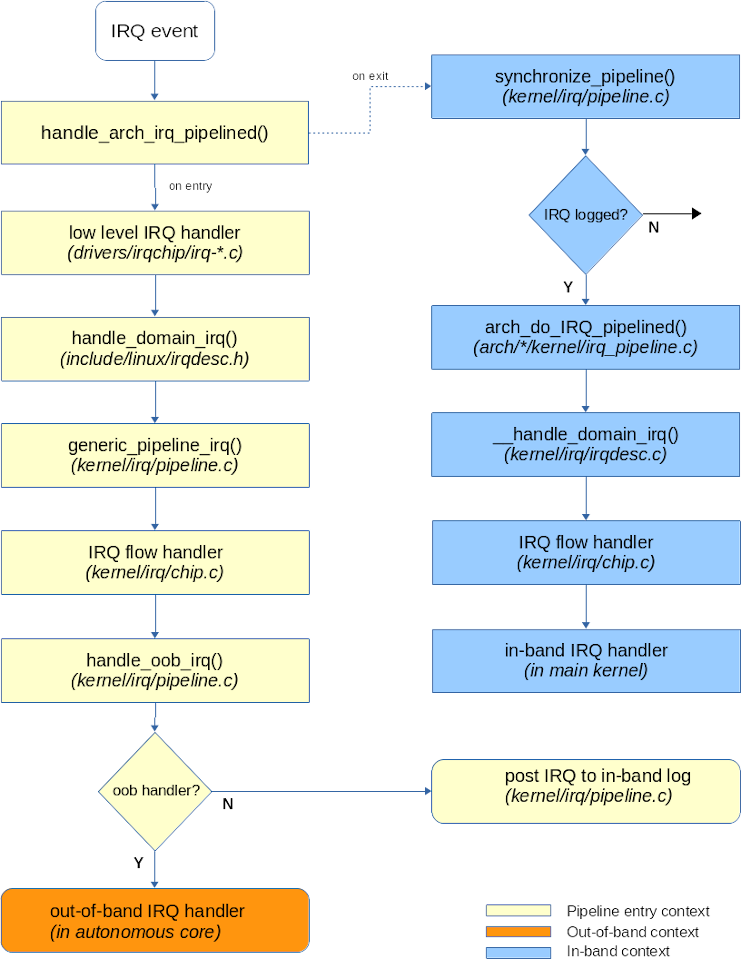
As illustrated above, interrupt flow handlers may run twice for a single IRQ in Dovetail’s pipelined interrupt model:
-
first to submit the event immediately to any out-of-band handler which may be interested in it. This is achieved by calling
handle_oob_irq(), whose role is to invoke such handler(s) if present, or schedule an in-band handling of the IRQ event if not. -
finally to run the in-band handler(s) accepting the IRQ event if it was not delivered to any out-of-band handler. To deliver the event to any in-band handler(s), the interrupt flow handler is called again by the pipeline core. When this happens, the flow handler processes the interrupt as usual, skipping the call to
handle_oob_irq()though.
Note
Any incoming IRQ event is either dispatched to one or more out-of-band handlers, or one or more in-band handlers, but never to a mix of them. Also, because every interrupt which is not handled by an out-of-band handler will end up into the in-band stage’s event log unconditionally, all external interrupts must have a handler in the in-band code - which should be the case for a sane kernel anyway.
Once generic_pipeline_irq() has returned, if the preempted execution
context was running over the in-band stage unstalled, the pipeline
core synchronizes the interrupt state immediately, meaning that all
IRQs found pending in the in-band stage’s log are immediately
delivered to their respective in-band handlers. In all other
situations, the IRQ frame is left immediately without running those
handlers. The IRQs may remain pending until the in-band code resumes
from preemption, then clears the virtual interrupt disable
flag,
which would cause the interrupt state to be synchronized, running the
in-band handlers eventually.
In-band IRQ delivery glue code
For delivering pending interrupts to the in-band stage, the generic
Dovetail core synchronizing the IRQ stage calls a routine named
arch_do_IRQ_pipelined(), which you must provide as part of the
pipeline’s arch-specific support code. This function is passed both
device IRQs and IPIs, it should dispatch the event accordingly
according to the following logic:
graph LR;
S(IRQ stage sync) --> E["arch_do_IRQ_pipelined()"]
style E fill:#99ccff;
E --> A{Is IPI?}
style A fill:#99ccff;
A -->|Yes| B[call IPI handler]
style B fill:#99ccff;
A -->|No| C["do_domain_irq()"]
style C fill:#99ccff;
For ARM and ARM64, the corresponding code looks like this:
void arch_do_IRQ_pipelined(struct irq_desc *desc)
{
struct pt_regs *regs = raw_cpu_ptr(&irq_pipeline.tick_regs);
unsigned int irq = irq_desc_get_irq(desc);
#ifdef CONFIG_SMP
/*
* Check for IPIs, handing them over to the specific dispatch
* code.
*/
if (irq >= OOB_IPI_BASE &&
irq < OOB_IPI_BASE + NR_IPI + OOB_NR_IPI) {
__handle_IPI(irq - OOB_IPI_BASE, regs);
return;
}
#endif
do_domain_irq(irq, regs);
}A couple of notes reading this code:
-
do_domain_irq()is a routine the generic Dovetail core implements, which fires the in-band handler for a device IRQ. -
How IPIs differentiate from other IRQs, which handler should be called for them is an arch-specific implementation you should provide in porting Dovetail. In the code example above, the IPI handling routine is named
__handle_IPI(). -
Since the interrupt delivery is deferred for the in-band stage until the latter is synchronized eventually, we don’t have access to the preempted register frame for a delayed interrupt event. Said differently, the interrupt context has already returned, only logging the interrupt event but not dispatching it yet, and the stack-based register frame of the preempted context is long gone. Fortunately, the kernel is normally only interested in analyzing frames attached to timer events (e.g. for profiling), so Dovetail only needs to save the register frame corresponding to the last tick event received to the per-CPU
irq_pipeline.tick_regsvariable. A pointer to such frame for the current CPU can be passed by your implementation ofarch_do_IRQ_pipelined()to the interrupt handler.
Deferring level-triggered IRQs
In absence of any out-of-band handler for the event, the device may keep asserting the interrupt signal until the cause has been lifted in its own registers. At the same time, we might not be allowed to run the in-band handler immediately over the current interrupt context if the in-band stage is currently stalled, we would have to wait for the in-band code to accept interrupts again. However, the interrupt disable bit in the CPU would certainly be cleared in the meantime. For this reason, depending on the interrupt type, the flow handlers as modified by the pipeline code may have to mask the interrupt line until the in-band handler has run from the in-band stage, lifting the interrupt cause. This typically happens with level-triggered interrupts, preventing the device from storming the CPU with a continuous interrupt request.
The pathological case
/* no OOB handler, in-band stage stalled on entry
leading to deferred dispatch to handler */
asm_irq_entry
...
-> generic_pipeline_irq()
...
<IRQ logged, delivery deferred>
asm_irq_exit
/*
* CPU allowed to accept interrupts again with IRQ cause not
* acknowledged in device yet => **IRQ storm**.
*/
asm_irq_entry
...
asm_irq_exit
asm_irq_entry
...
asm_irq_exitSince all of the IRQ handlers sharing an interrupt line are either in-band or out-of-band in a mutually exclusive way, such masking cannot delay out-of-band events.
Tip
The logic behind masking interrupt lines until events are processed at
some point later - out of the original interrupt context - applies
exactly the same way to the threaded interrupt model
(i.e. IRQF_THREAD). In this case, interrupt lines may be masked
until the IRQ thread is scheduled in, after the interrupt handler
clears the event cause eventually.
Adapting the interrupt flow handlers to pipelining
The logic for adapting flow handlers dealing with interrupt pipelining is composed of the following steps:
-
(optionally) enter the critical section protected by the IRQ descriptor lock, if the interrupt is shared among processors (e.g. device interrupts). If so, check if the interrupt handler may run on the current CPU (
irq_may_run()). By definition, no locking would be required for per-CPU interrupts. -
check whether we are entering the pipeline in order to deliver the interrupt to any out-of-band handler registered for it.
on_pipeline_entry()returns a boolean value denoting this situation. -
if on pipeline entry, we should pass the event on to the pipeline core by calling
handle_oob_irq(). Upon return, this routine tells the caller whether any out-of-band handler was fired for the event.-
if so, we may assume that the interrupt cause is now cleared in the device, and we may leave the flow handler, after having restored the interrupt line into a normal state. In case of a level-triggered interrupt which has been masked on entry to the flow handler, we need to unmask the line before leaving.
-
if no out-of-band handler was called, we should have performed any acknowledge and/or EOI to release the interrupt line in the controller, while leaving it masked if required before exiting the flow handler. In case of a level-triggered interrupt, we do want to leave it masked for solving the pathological case with interrupt deferral explained earlier.
-
-
if not on pipeline entry (i.e. second entry of the flow handler), then we must be running over the in-band stage, accepting interrupts, therefore we should fire the in-band handler(s) for the incoming event.
Example: adapting the handler dealing with level-triggered IRQs
--- a/kernel/irq/chip.c
+++ b/kernel/irq/chip.c
void handle_level_irq(struct irq_desc *desc)
{
raw_spin_lock(&desc->lock);
mask_ack_irq(desc);
if (!irq_may_run(desc))
goto out_unlock;
+ if (on_pipeline_entry()) {
+ if (handle_oob_irq(desc))
+ goto out_unmask;
+ goto out_unlock;
+ }
+
desc->istate &= ~(IRQS_REPLAY | IRQS_WAITING);
/*
@@ -642,7 +686,7 @@ void handle_level_irq(struct irq_desc *desc)
kstat_incr_irqs_this_cpu(desc);
handle_irq_event(desc);
-
+out_unmask:
cond_unmask_irq(desc);
out_unlock:
raw_spin_unlock(&desc->lock);
}This change reads as follows:
-
on entering the pipeline, which means immediately over the interrupt frame context set up by the CPU for receiving the event, tell the pipeline core about the incoming IRQ.
-
if this IRQ was handled by an out-of-band handler (
handle_oob_irq()returns true), consider the event to have been fully processed, unmasking the interrupt line before leaving. We can’t do more than this, simply because the in-band kernel code might expect not to receive any interrupt at this point (i.e. the virtual interrupt disable flag might be set for the in-band stage). -
otherwise, keep the interrupt line masked until
handle_level_irq()is called again from a safe context for handling in-band interrupts, at which point the event should be delivered to the in-band interrupt handler of the main kernel. We have to keep the line masked to prevent the IRQ storm which would certainly happen otherwise, since no handler has cleared the cause of the interrupt event in the device yet.
Fixing up the IRQ chip drivers
We must make sure the following handlers exported by irqchip drivers
can operate over the out-of-band context safely:
irq_mask()irq_ack()irq_mask_ack()irq_eoi()irq_unmask()
For so-called device interrupts, no change is required, because the
genirq layer ensures a single CPU at most handles a given IRQ event
by holding the per-descriptor irq_desc::lock spinlock across calls
to those irqchip handlers, and such lock is automatically turned
into an hybrid spinlock when pipelining
interrupts. In other words, those handlers are properly serialized,
running with interrupts disabled in the CPU as their non-pipelined
implementation expects it.
Unlike for device interrupts, per-CPU interrupt handling does not need to be serialized this way, since by definition, there cannot be multiple CPUs racing for access with such type of events.
However, there might other reasons to fix up some of those handlers:
-
they must not invoke any in-band kernel service, which might cause an invalid context re-entry.
-
there may be inner spinlocks locally defined by some
irqchipdrivers for serializing access to a common interrupt controller hardware for distinct IRQs which are handled by multiple CPUs concurrently. Adapting such spinlocked sections found inirqchipdrivers to support interrupt pipelining may involve converting the related spinlocks to hard spinlocks.
Other section of code which were originally serialized by common
interrupt disabling may need to be made fully atomic for running
consistenly in pipelined interrupt mode. This can be done by
introducing hard masking, converting local_irq_save() calls to
hard_local_irq_save(), conversely local_irq_restore() to
hard_local_irq_restore().
Finally, IRQCHIP_PIPELINE_SAFE must be added to the struct irqchip::flags member of a pipeline-aware irqchip driver, in order
to notify the kernel that such controller can operate in pipelined
interrupt mode. Even if you did not introduce any other change to
support pipelining, this one is required: it tells the kernel that you
did review the code for that purpose.
Adapting the ARM GIC driver to interrupt pipelining
--- a/drivers/irqchip/irq-gic.c
+++ b/drivers/irqchip/irq-gic.c
@@ -93,7 +93,7 @@ struct gic_chip_data {
#ifdef CONFIG_BL_SWITCHER
-static DEFINE_RAW_SPINLOCK(cpu_map_lock);
+static DEFINE_HARD_SPINLOCK(cpu_map_lock);
#define gic_lock_irqsave(f) \
raw_spin_lock_irqsave(&cpu_map_lock, (f))
@@ -424,7 +424,8 @@ static const struct irq_chip gic_chip = {
.irq_set_irqchip_state = gic_irq_set_irqchip_state,
.flags = IRQCHIP_SET_TYPE_MASKED |
IRQCHIP_SKIP_SET_WAKE |
- IRQCHIP_MASK_ON_SUSPEND,
+ IRQCHIP_MASK_ON_SUSPEND |
+ IRQCHIP_PIPELINE_SAFE,
};
void __init gic_cascade_irq(unsigned int gic_nr, unsigned int irq)Adapting the BCM2835 pin control driver to interrupt pipelining
--- a/drivers/pinctrl/bcm/pinctrl-bcm2835.c
+++ b/drivers/pinctrl/bcm/pinctrl-bcm2835.c
@@ -79,7 +79,7 @@ struct bcm2835_pinctrl {
struct gpio_chip gpio_chip;
struct pinctrl_gpio_range gpio_range;
- raw_spinlock_t irq_lock[BCM2835_NUM_BANKS];
+ hard_spinlock_t irq_lock[BCM2835_NUM_BANKS];
};
/* pins are just named GPIO0..GPIO53 */
@@ -608,6 +608,7 @@ static struct irq_chip bcm2835_gpio_irq_chip = {
.irq_ack = bcm2835_gpio_irq_ack,
.irq_mask = bcm2835_gpio_irq_disable,
.irq_unmask = bcm2835_gpio_irq_enable,
+ .flags = IRQCHIP_PIPELINE_SAFE,
};In some (rare) cases, we might have a bit more work for adapting an
interrupt chip driver. For instance, we might have to convert a
sleeping spinlock to a raw spinlock first, so that we can convert the
latter to a hard spinlock eventually. Hard spinlocks like raw ones
should be manipulated via the raw_spin_lock() API, unlike sleeping
spinlocks.
Note
irq_set_chip() will complain loudly with a kernel warning whenever
the irqchip descriptor passed does not bear the
IRQCHIP_PIPELINE_SAFE flag and CONFIG_IRQ_PIPELINE is enabled. Take
this warning as a sure sign that your port of the IRQ pipeline to the
target system is incomplete.
Kernel preemption control (CONFIG_PREEMPT)
When pipelining is enabled, Dovetail ensures preempt_schedule_irq()
reconciles the virtual interrupt state - which has not been touched by
the assembly level code upon kernel entry - with basic assumptions
made by the scheduler core, such as entering with interrupts virtually
disabled (i.e. the in-band stage should be stalled).
