Scheduling
The out-of-band scheduler
EVL defines five scheduling policies for running out-of-band threads. These policies are hierarchized: every time the core needs to pick the next eligible thread to run on the current CPU, it queries each policy module for a runnable thread in the following order:
-
SCHED_FIFO, which is the common first-in, first-out real-time policy.
-
SCHED_RR round-robin policy internally.
-
SCHED_TP, which enforces temporal partitioning of multiple sets of threads in a way which prevents those sets from overlapping time-wise on the CPU which runs such policy.
-
SCHED_QUOTA, which enforces a limitation on the CPU consumption of threads over a fixed period of time.
-
SCHED_WEAK, which is a non real-time policy allowing its members to run in-band most of the time, while retaining the ability to request EVL services.
-
SCHED_IDLE, which is the fallback option the EVL core considers only when other policies have no runnable task on the CPU. This policy is not directly available to the user.
The SCHED_QUOTA and SCHED_TP policies are optionally supported by the
core, make sure to enable CONFIG_EVL_SCHED_QUOTA or
CONFIG_EVL_SCHED_TP respectively in the kernel configuration if you
need them.
Tip
Before a thread can be assigned to any EVL class, it must attach itself to the core by a call to evl_attach_thread.
Scheduler services
This call changes the scheduling attributes for the thread referred to by efd in the EVL core.
A file descriptor referring to the target thread, as returned by evl_attach_thread(), evl_get_self(), or opening a thread element device in /dev/evl/thread using open(2).
A structure defining the new set of attributes, which depends
on the scheduling policy mentioned in
attrs->sched_policy. EVL currently implement the following
policies:
-
SCHED_FIFO, which is the common first-in, first-out real-time policy.
-
SCHED_RR, defining a real-time, round-robin policy in which each member of the class is allotted an individual time quantum before the CPU is given to the next thread.
-
SCHED_TP, which enforces temporal partitioning of multiple sets of threads based on a cycle-based scheduling.
-
SCHED_QUOTA, which enforces a limitation on the CPU consumption of threads over a fixed period of time, known as the global quota period. Threads undergoing this policy are pooled in groups, with each group being given a share of the period.
-
SCHED_WEAK, which is a non real-time policy allowing its members to run in-band most of the time, while retaining the ability to request EVL services, at the expense of briefly switching to the out-of-band execution stage on demand.
evl_set_schedattr() returns zero on success, otherwise a negated error code is returned:
-EBADF efd is not a valid thread descriptor.
-EINVAL Some of the parameters in attrs are wrong. Check
attrs->sched_policy, and the policy-specific
information may EVL expect for more.
-ESTALE efd refers to a stale thread, see these notes.
evl_set_schedattr() immediately applies the changes to the scheduling attributes of the target thread when the latter runs in out-of-band context. Later on, the next time such thread transitions from out-of-band to in-band context, the in-band kernel will apply a translated version of those changes to its own scheduler as well.
The translation of the out-of-band scheduling attributes passed to evl_set_schedattr() to the in-band ones applied by the mainline kernel works as follows:
| out-of-band policy | in-band policy |
|---|---|
| SCHED_FIFO, prio | SCHED_FIFO, prio |
| SCHED_RR, prio | SCHED_FIFO, prio |
| SCHED_TP, prio | SCHED_FIFO, prio |
| SCHED_QUOTA, prio | SCHED_FIFO, prio |
| SCHED_WEAK, prio > 0 | SCHED_FIFO, prio |
| SCHED_WEAK, prio == 0 | SCHED_OTHER |
Warning
Calling pthread_setschedparam(3) from the C library does not affect the scheduling attributes of an EVL thread. It only affects the scheduling parameters of such thread from the standpoint of the in-band kernel. Because the C library may cache the current scheduling attributes for the in-band context of a thread - glibc does so typically - the cached value may not reflect the actual scheduling attributes of the thread after this call.
This is the call for retrieving the current scheduling attributes of the thread referred to by efd.
A file descriptor referring to the target thread, as returned by
evl_attach_thread(),
evl_get_self(), or opening a
thread element device in /dev/evl/thread using open(2).
A pointer to a structure where the EVL core should write back the scheduling attributes.
#include <evl/sched.h>
#include <evl/thread.h>
int retrieve_self_schedparams(void)
{
struct evl_sched_attrs attrs;
return evl_get_schedattr(evl_get_self(), &attrs);
}The value returned in attrs.sched_priority is the base priority
level of the thread within its scheduling class, which does not
reflect any priority inheritance/ceiling boost that might be ongoing.
evl_get_schedattr() returns zero on success, otherwise a negated error code is returned:
-EBADF efd is not a valid thread descriptor.
-ESTALE efd refers to a stale thread, see these notes.
Some policies require specific configuration for each CPU, evl_control_sched() passes such information to the core. Which parameters should be filled into the param union depends on the policy. For instance, you would need to call this routine for defining the SCHED_TP schedule on a given CPU.
Either SCHED_QUOTA or SCHED_TP.
A pointer to the scheduling parameters which should be applied to cpu for the policy mentioned. These parameters are described in the SCHED_QUOTA and SCHED_TP documentation.
A pointer to a control information block where the core may write some useful data about the current settings. Except for the get operations, this pointer is optional and may be passed as NULL.
A CPU which belongs to the set of CPUs EVL runs out-of-band activity
on (see the evl.oobcpus kernel parameter).
This call returns zero on success, or a negated error code:
-
-EINVAL Either policy, cpu, or some information in param is wrong.
-
-EFAULT Either param or info are invalid addresses.
-
-ENOMEM The core could not allocate memory for carrying out the operation. Scary.
-
-EOPNOTSUPP policy is valid but not available from the core.
CONFIG_EVL_SCHED_TPorCONFIG_EVL_SCHED_QUOTAare likely disabled in the kernel configuration.
In some cases, EVL threads undergoing the SCHED_FIFO or SCHED_RR
policies might need to perform manual round-robin, like
sched_yield()
allows for plain POSIX threads. evl_yield() can be used for that purpose.
Manual round-robin moves the caller at the end of its priority group, yielding the CPU to other threads with the same priority. If there are none, then evl_yield() returns immediately with no effect.
Tip
Although that would work, calling evl_yield() for a thread undergoing the SCHED_WEAK policy would make no sense. In that case, the caller would be immediately demoted to the in-band stage on return from the call, leaving the EVL scheduler right after it was promoted to the out-of-band stage for executing evl_yield(). Pretty much a useless CPU burner with no upside.
On success, evl_yield() returns zero, otherwise a negated error code:
-EPERM The caller is not attached to the EVL core.
Scheduling policies
SCHED_FIFO policy
The first-in, first-out policy, fixed priority, preemptive scheduling policy. If you really need a refresher about this one, you can still have a look at this inspirational piece of post-modern poetry for background info. Or you can just go for the short version: with SCHED_FIFO, the scheduler always picks the runnable thread with the highest priority which spent the longest time waiting for the CPU to be available.
EVL provides 99 fixed priority levels starting a 1, which maps 1:1 to the in-band kernel’s SCHED_FIFO implementation as well.
Setting the SCHED_FIFO parameters
Switching a thread to FIFO scheduling is achieved by calling
evl_set_schedattr() with the
file descriptor of the target thread. The evl_sched_attrs attribute
structure should be filled in as follows:
#include <evl/sched.h>
struct evl_sched_attrs attrs;
int ret;
attrs.sched_policy = SCHED_FIFO;
attrs.sched_priority = <priority>; /* [1-99] */
ret = evl_set_schedattr(efd, &attrs);SCHED_RR policy
The round-robin policy is based on SCHED_FIFO internally. Additionally, it limits the execution time of its members to a given timeslice, moving a thread which fully consumed its current timeslice to the tail of the scheduling queue for its priority level. This is designed as a simple way to prevent threads from over-consuming the CPU within their own priority level.
Unlike the in-band kernel which defines a global timeslice value for all members of the SCHED_RR class, EVL defines a per-thread quantum instead. Since EVL is tickless, this quantum may be any valid duration, and may differ among threads from the same priority group.
Setting the SCHED_RR parameters
Switching a thread to round-robin scheduling is achieved by calling
evl_set_schedattr() with the
file descriptor of the target thread. The evl_sched_attrs attribute
structure should be filled in as follows:
#include <evl/sched.h>
struct evl_sched_attrs attrs;
int ret;
attrs.sched_policy = SCHED_RR;
attrs.sched_priority = <priority>; /* [1-99] */
attrs.sched_rr_quantum = (struct timespec){
.tv_sec = <seconds>,
.tv_nsec = <nanoseconds>,
};
ret = evl_set_schedattr(efd, &attrs);SCHED_QUOTA policy
The quota-based policy enforces a limitation on the CPU consumption of threads over a fixed period of time, known as the global quota period. Threads undergoing this policy are pooled in groups, with each group being given a share of the period (expressed as a percentage). Within a SCHED_QUOTA group, the SCHED_FIFO policy applies to all its members.
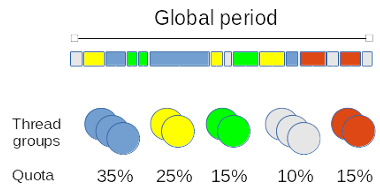
For instance, say that we have five distinct thread groups, each of which is given a runtime budget which represents a portion of the global period: 35%, 25%, 15%, 10% and finally 5% of a global period set to one second. The first group would be allotted 350 milliseconds over a second, the second group would get 250 milliseconds from the same period and so on.
Every time a thread undergoing the SCHED_QUOTA policy is given the CPU, the time it consumes is charged to the group it belongs to. Whenever the group as a whole reaches the alloted time budget, all its members stall until the next period starts, at which point the runtime budget of every group is replenished for the next round of execution, resuming all its members in the process.
You may attach as many threads as you need to a single group, and the number of threads may vary among groups. The alloted runtime quota for a group is decreased by the execution time of every thread in that group. Therefore, a group with no thread does not consume its quota.
Runtime budget and peak quota
Each thread group is given its full quota every time the global period starts, according to the configuration set for this group. If the group did not consume its quota entirely by the end of the current period, the remaining budget is added to the group’s quota for the next period, up to a limit defined as the peak quota. If the accumulated budget would cause the quota to exceed the peak value, the extra time is spread over multiple subsequent periods until the budget is fully consumed.
Managing quota scheduling groups
Creating, modifying and removing thread groups is achieved by calling evl_control_sched().
Creating a quota group
EVL supports up to 1024 distinct thread groups for quota-based
scheduling system-wide. Each thread group is assigned to a specific
CPU by the application code which creates it, among the set of CPUs
EVL runs out-of-band activity on (see the evl.oobcpus kernel
parameter).
A thread group is represented by a unique integer returned by the core upon creation, aka the group identifier.
Creating a new thread group is achieved by calling
evl_control_sched(). Some
information including the new group identifier is returned in the
ancillary evl_sched_ctlinfo structure passed to the request. The
evl_sched_ctlparams control structure should be filled in as
follows:
#include <evl/sched.h>
union evl_sched_ctlparam param;
union evl_sched_ctlinfo info;
int ret;
param.quota.op = evl_quota_add;
ret = evl_control_sched(SCHED_QUOTA, ¶m, &info, <cpu-number>);On success, the following information is received from the core regarding the new group:
-
info.quota.tgid contains the new group identifier.
-
info.quota.quota_percent is the current percentage of the global period allotted to the new group. At creation time, this value is set to 100%. You may want to change it to reflect the final value.
-
info.quota.quota_peak_percent reflects the current peak percentage of the global period allotted to the new group, which is also set to 100% at creation time. This means that by default, a new group might double its quota value by accumulating runtime budget, consuming up to 100% of the CPU time during the next period. Likewise, you may want to change it to reflect the final value.
-
info.quota.quota_sum is the sum of the quota values of all groups assigned to the CPU specified in the evl_control_sched() request. This gives the overall CPU business as far as SCHED_QUOTA is concerned. This sum should not exceed 100% for a CPU in a properly configured system.
Modifying a quota group
Removing a quota group
Setting the SCHED_QUOTA parameters
Switching a thread to quota-based scheduling is achieved by calling
evl_set_schedattr() with the
file descriptor of the target thread, in order to attach such thread
to a quota group along with setting its priority. To do so, the
evl_sched_attrs attribute structure should be filled in as follows:
#include <evl/sched.h>
struct evl_sched_attrs attrs;
int ret;
attrs.sched_policy = SCHED_QUOTA;
attrs.sched_priority = <priority>; /* [1-99] */
attrs.sched_quota_group = <grpid>; /* Quota group id. */
ret = evl_set_schedattr(efd, &attrs);SCHED_TP policy
This policy enforces a so-called temporal partitioning, which is a way to schedule thread activities on a given CPU so that they cannot overlap time-wise. To this end, the policy defines a global, major time frame of fixed duration repeating cyclically, which is divided into smaller minor frames or time windows also of fixed durations, but not necessarily equal. Therefore, a minor frame is bounded by its time offset from the beginning of the major frame, and its own duration. The sum of all minor frame durations defines the duration of the global time frame.
Each minor frame contributes to the run-time allotted within the
global time frame to a group of thread called a partition. The
maximum number of partitions in the system is defined by
CONFIG_EVL_TP_NR_PART in the kernel configuration. Each thread
undergoing this policy is attached to one of such partitions.
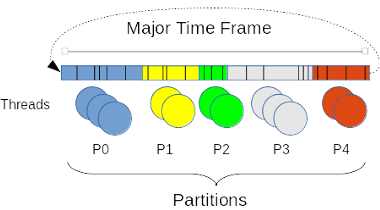
When a minor frame elapses on a CPU, the threads attached to its partition are immediately suspended, and threads from the partition assigned to the next minor frame may be picked for scheduling. When the last minor frame elapses, the process repeats from the minor frame leading the major time frame. You may assign as many threads as you need to a single partition, and the number of threads may vary among partitions. A partition with no thread simply runs no SCHED_TP thread until the next minor frame assigned a non-empty partition starts.
Tip
Valid partition numbers range from 0 to CONFIG_EVL_TP_NR_PART - 1. The special partition number EVL_TP_IDLE can be used when
configuring the scheduler to designate the idle partition when
assigning it to a minor frame, creating a time hole in the schedule
which will not run any SCHED_TP thread until this minor frame elapses.
Setting the temporal partitioning information for a CPU
Temporal partitioning is defined on a per-CPU basis, you have to configure each CPU involved in this policy independently, enumerating the minor frames which compose the major one as follows:
union evl_sched_ctlparam param;
int ret;
param.tp.op = evl_tp_install;
param.tp.nr_windows = <number_of_minor_frames>;
param.tp.windows[0].offset = <offset_from_start_of_major_frame>;
param.tp.windows[0].duration = <duration_of_minor_frame>;
param.tp.windows[0].ptid = <assigned_partition_id>;
...
param.tp.windows[<number_of_minor_frames> - 1].offset = <offset_from_start_of_major_frame>;
param.tp.windows[<number_of_minor_frames> - 1].duration = <duration_of_minor_frame>;
param.tp.windows[<number_of_minor_frames> - 1].ptid = <assigned_partition_id>;
ret = evl_control_sched(SCHED_TP, ¶m, NULL, <cpu-number>);If the special value EVL_TP_IDLE is assigned to a minor time frame
(ptid), no thread undergoing the SCHED_TP policy will run until such
frame elapses. This is a way to create a time hole within the major
time frame.
This operation implicitly overrides the previous TP settings for the CPU, leaving the TP scheduling in stopped state. Generally speaking, once a TP scheduling plan is installed for a CPU, it is left in standby mode until explicitly started.
No information is passed back by the core when installing a TP schedule, you may pass the info parameter as NULL to evl_control_sched().
Starting the TP scheduling on a CPU
The following request enables the TP scheduler for the given CPU; you have to issue this request for activating a TP scheduling plan:
union evl_sched_ctlparam param;
int ret;
param.tp.op = evl_tp_start;
ret = evl_control_sched(SCHED_TP, ¶m, NULL, <cpu-number>);No information is passed back by the core when starting a TP scheduling plan, you may pass the info parameter as NULL to evl_control_sched().
Stopping the TP scheduling on a CPU
You can disable the scheduling of threads undergoing the SCHED_TP policy on a CPU by the following call:
union evl_sched_ctlparam param;
int ret;
param.tp.op = evl_tp_stop;
ret = evl_control_sched(SCHED_TP, ¶m, NULL, <cpu-number>);Upon success, the target CPU won’t be considered for running SCHED_TP
threads, until the converse request evl_tp_start is received for
that CPU.
No information is passed back by the core when stopping a TP scheduling plan, you may pass the info parameter as NULL to evl_control_sched().
Retrieving the temporal partitioning information from a CPU
The following request fetches the current scheduling plan for a given CPU:
union evl_sched_ctlparam param;
struct {
union evl_sched_ctlinfo info;
struct __sched_tp_window windows[<max_number_of_minor_frames>];
} result;
int ret;
param.tp.op = evl_tp_get;
param.tp.nr_windows = <max_number_of_minor_frames>;
ret = evl_control_sched(SCHED_TP, ¶m, &result.info, <cpu-number>);param.nr_windows[] specifies the maximum number of minor frames the
EVL core should dump into the result.info.nr_windows[] output
variable array. This value is automatically capped to the actual
number of minor frames defined for the target CPU at the time of the
call.
The minor frames active for the target CPU are readable from the
result.windows[] array, up to param.nr_windows[] . The number of
valid elements in this array is given by result.info.nr_windows[].
Removing the temporal partitioning information from a CPU
This is the converse operation to evl_tp_install, removing temporal
partitioning support for the target CPU, releasing all related
resources. This request implicitly stops the TP scheduling on such CPU
prior to uninstalling.
Setting the SCHED_TP parameters
Switching a thread to temporal partitioning is achieved by calling
evl_set_schedattr() with the
file descriptor of the target thread. The evl_sched_attrs attribute
structure should be filled in as follows:
#include <evl/sched.h>
struct evl_sched_attrs attrs;
int ret;
attrs.sched_policy = SCHED_TP;
attrs.sched_priority = <priority>; /* [1-99] */
attrs.sched_tp_partition = <ptid>; /* Partition id. */
ret = evl_set_schedattr(efd, &attrs);ptid should be a valid partition identifier between 0 and
CONFIG_EVL_TP_NR_PART - 1.
Within a minor time frame, threads undergo the SCHED_FIFO policy according to their fixed priority value.
SCHED_WEAK policy
You may want to run some POSIX threads in-band most of the time, except when they need to call some EVL services occasionally. Occasionally here means either non-repeatedly, or at any rate not from a high frequency loop.
Members of this class are picked second to last in the hierarchy of EVL scheduling classes, right before the sole member of the SCHED_IDLE class which stands for the in-band execution stage of the kernel. The priority such threads have in the in-band context are preserved by this policy when they (normally briefly) run on the out-of-band execution stage. For this reason, SCHED_WEAK threads have a fixed priority ranging from 0 to 99 included, which maps to in-band SCHED_OTHER (0), SCHED_FIFO and SCHED_RR (1-99) priority ranges.
A thread scheduled in the SCHED_WEAK class may invoke any EVL service, including blocking ones for waiting for out-of-band events (e.g. depleting a semaphore), which will certainly switch it to the out-of-band execution stage. Before returning from the EVL system call, the thread will be automatically switched back to the in-band execution stage by the core. This means that each and every EVL system call issued by a thread assigned to the SCHED_WEAK class is going to trigger two execution stage switches back and forth, which is definitely costly. So make sure not to use this feature in any high frequency loop.
Warning
In a specific case the EVL core will keep the thread running on the out-of-band execution stage though: whenever this thread has returned from a successful call to evl_lock_mutex(), holding an EVL mutex. This ensures no in-band activity on the same CPU can preempt the lock owner, which would certainly lead to a priority inversion would that lock be contended later on by another EVL thread. The lock owner is eventually switched back to in-band mode by the core as a result of releasing the last EVL mutex it was holding.
There are only a few legitimate use cases for assigning an EVL thread to the SCHED_WEAK scheduling class:
-
as part of some initialization, cleanup or any non real-time phase of your application, a thread needs to synchronize with another EVL thread which belongs to a real-time class like SCHED_FIFO.
-
some in-band thread which purpose is to handle fairly exceptional events needs to be notified by a real-time thread to do so.
In all other cases where an in-band thread might need to be driven by out-of-band events which may occur at a moderate or higher rate, using a message-based mechanism such as a cross-buffer is the best way to go.
Also note that some EVL services may be called by regular POSIX
threads. Typically, a plain POSIX thread may post an EVL
semaphore for
signaling an out-of-band EVL thread pending on it. You can find the
allowed calling contexts for each EVL service from libevl
there.
Switching a thread to SCHED_WEAK is achieved by calling
evl_set_schedattr() with the
file descriptor of the target thread. The evl_sched_attrs attribute
structure should be filled in as follows:
#include <evl/thread.h>
struct evl_sched_attrs attrs;
int ret;
attrs.sched_policy = SCHED_WEAK;
attrs.sched_priority = <priority>; /* [0-99] */
ret = evl_set_schedattr(efd, &attrs);SCHED_IDLE policy
The idle class has a single task on each CPU: the low priority placeholder task.
SCHED_IDLE has the lowest priority among policies, its sole task is picked for scheduling only when other policies have no runnable task on the CPU. A task member of the SCHED_IDLE class cannot block, it is always runnable.
This is an internal class, which is neither available to user applications nor drivers.
