Kernel API
The autonomous core has to act upon device interrupts with no delay, regardless of the other kernel operations which may be ongoing when the interrupt is received by the CPU. Therefore, there is a basic requirement for prioritizing interrupt masking and delivery between the autonomous core and GPOS operations, while maintaining consistent internal serialization for the kernel.
However, to protect from deadlocks and maintain data integrity, Linux hard disables interrupts around any critical section of code which must not be preempted by interrupt handlers on the same CPU, enforcing a strictly serialized execution among those contexts. The unpredictable delay this may cause before external events can be handled is a major roadblock for kernel components requiring predictable and very short response times to external events, in the range of a few microseconds.
To address this issue, Dovetail introduces a mechanism called interrupt pipelining which turns all device IRQs into pseudo-NMIs, only to run NMI-safe interrupt handlers from the perspective of the main kernel activities. This is achieved by substituting real interrupt masking in a CPU by a software-based, virtual interrupt masking when the in-band stage is active on such CPU. This way, the autonomous core can receive IRQs as long as it did not mask interrupts in the CPU, regardless of the virtual interrupt state maintained by the in-band side. Dovetail monitors the virtual state to decide when IRQ events should be allowed to flow down to the in-band stage where the main kernel executes. This way, the assumptions the in-band code makes about running interrupt-free or not are still valid.
Two-stage IRQ pipeline
Interrupt pipelining is a lightweight approach based on the
introduction of a separate, high-priority execution stage for running
out-of-band interrupt handlers immediately upon IRQ receipt, which
cannot be delayed by the in-band, main kernel work. By immediately,
we mean unconditionally, regardless of whether the in-band kernel code
had disabled interrupts when the event arrived, using the common
local_irq_save(), local_irq_disable() helpers or any of their
derivatives. IRQs which have no handlers in the high priority stage
may be deferred on the receiving CPU until the out-of-band activity
has quiesced on that CPU. Eventually, the preempted in-band code can
resume normally, which may involve handling the deferred interrupts.
In other words, interrupts are flowing down from the out-of-band to the in-band interrupt stages, which form a two-stage pipeline for prioritizing interrupt delivery. The runtime context of the out-of-band interrupt handlers is known as the out-of-band stage of the pipeline, as opposed to the in-band kernel activities sitting on the in-band stage:
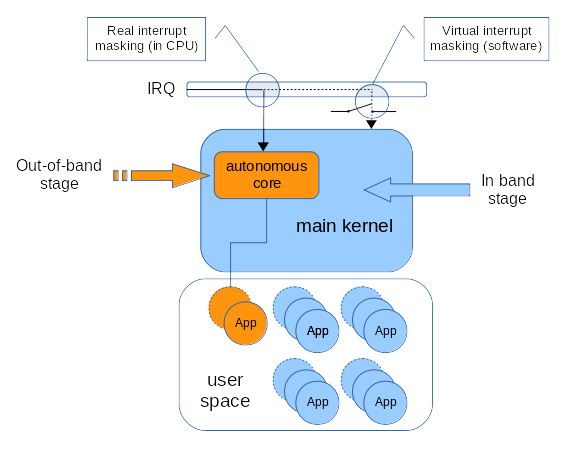
An autonomous core can base its own activities on the out-of-band stage, interposing on specific IRQ events, for delivering real-time capabilities to a particular set of applications. Meanwhile, the main kernel operations keep going over the in-band stage unaffected, only delayed by short preemption times for running the out-of-band work.
Optimistic interrupt protection
Predictable response time of out-of-band handlers to IRQ receipts requires the in-band kernel work not to be allowed to delay them by masking interrupts in the CPU.
However, critical sections delimited this way by the in-band code must still be enforced for the in-band stage, so that system integrity is not at risk. This means that although out-of-band IRQ handlers may run at any time while the out-of-band stage is accepting interrupts, in-band IRQ handlers should be allowed to run only when the in-band stage is accepting interrupts too. So we need to decouple the interrupt masking and delivery logic which applies to the out-of-band stage from the one in effect on the in-band stage, by implementing a dual interrupt control.
In the pipelined interrupt model, the CPU can receive interrupts most of the time, but the delivery logic of those events may be deferred by a software mechanism until the kernel actually accepts them. This approach is said to be optimistic because it is assumed that the overhead of maintaining such mechanism should be small as the in-band code seldom receives an interrupt while masking them.
This approach was fully described by Stodolsky, Chen & Bershad in Fast Interrupt Priority Management in Operating System Kernels.
Virtual interrupt disabling
To this end, a software logic managing a virtual interrupt disable
flag is introduced by the interrupt pipeline between the hardware and
the generic IRQ management layer. This logic can mask IRQs from the
perspective of the in-band kernel work when local_irq_save(),
local_irq_disable() or any lock-controlled masking operations like
spin_lock_irqsave() is called, while still accepting IRQs from the
CPU for immediate delivery to out-of-band handlers.
When a real IRQ arrives while interrupts are virtually masked, the event is logged for the receiving CPU, kept there until the virtual interrupt disable flag is cleared at which point it is dispatched as if it just happened. The principle of deferring interrupt delivery based on a software flag coupled to an event log has been originally described as Optimistic interrupt protection in this paper. It was originally intended as a low-overhead technique for manipulating the processor interrupt state, reducing the cost of interrupt masking for the common case of absence of interrupts.
In Dovetail’s two-stage pipeline, the out-of-band stage protects from interrupts by disabling them in the CPU’s status register as usual, while the in-band stage disables interrupts only virtually. A stage for which interrupts are disabled is said to be stalled. Conversely, unstalling a stage means re-enabling interrupts for it.
Warning
Obviously, stalling the out-of-band stage implicitly means disabling further IRQ receipts for the in-band stage down the pipeline too.
Interrupt deferral for the in-band stage
When the in-band stage is stalled because the virtual interrupt disable flag is set, any IRQ event which was not immediately delivered to the out-of-band stage is recorded into a per-CPU log, postponing delivery to the in-band kernel handler.
Such delivery is deferred until the in-band kernel code clears the
virtual interrupt disable flag by calling local_irq_enable() or any
of its variants, which unstalls the in-band stage. When this happens, the
interrupt state is resynchronized by playing the log, firing the
in-band handlers for which an IRQ event is pending.
/* Both stages unstalled on entry */
local_irq_save(flags);
<IRQx received: no out-of-band handler>
(pipeline logs IRQx event)
...
local_irq_restore(flags);
(pipeline plays IRQx event)
handle_IRQx_interrupt();If the in-band stage is unstalled at the time of the IRQ receipt, the in-band handler is immediately invoked, just like with the non-pipelined IRQ model.
All interrupts are (seemingly) NMIs
From the standpoint of the in-band kernel code (i.e. the one running over the in-band interrupt stage) , the interrupt pipelining logic virtually turns all device IRQs into NMIs, for running out-of-band handlers.
For this reason, out-of-band code may generally not re-enter in-band code, for preventing creepy situations like this one:
/* in-band context */
spin_lock_irqsave(&lock, flags);
<IRQx received: out-of-band handler installed>
handle_oob_event();
/* attempted re-entry to in-band from out-of-band. */
in_band_routine();
spin_lock_irqsave(&lock, flags);
<DEADLOCK>
...
...
...
...
spin_unlock irqrestore(&lock, flags);Even in absence of an attempt to get a spinlock recursively, the outer in-band code in the example above is entitled to assume that no access race can occur on the current CPU while interrupts are (virtually) masked for the in-band stage. Re-entering in-band code from an out-of-band handler would invalidate this assumption.
In rare cases, we may need to fix up the in-band kernel routines in order to allow out-of-band handlers to call them. Typically, generic atomic helpers are such routines, which serialize in-band and out-of-band callers.
For all other cases, the IRQ work API is available for scheduling the execution of a routine from the out-of-band stage, which will be invoked later from a safe place on the in-band stage as soon as it gets back in control on the current CPU (i.e. typically when in-band interrupts are allowed again).
Pipeline entry context
The pipeline entry denotes the code which runs in order to accept a hardware interrupt, either dispatching it to its out-of-band handler immediately, or logging it as a pending event for the in-band stage. This runtime section starts from the call to handle_irq_pipeline_prepare(), ends after the call to handle_irq_pipeline_finish(). These calls are issued by the architecture code every time it wants to feed the pipeline upon an incoming hardware interrupt.
Pipelining and RCU
As described earlier, from the standpoint of the in-band context, an interrupt entry is unsafe in a similar way a NMI is when pipelining is in effect, since it may preempt almost anywhere as IRQs are only virtually masked most of the time, including inside (virtually) interrupt-free sections.
For this reason, Dovetail declares a (pseudo-)NMI entry to RCU when a hardware interrupt is fed to the pipeline, so that it may enter RCU read sides to safely access RCU-protected data. Typically, handle_domain_irq() would need this guarantee to resolve IRQ mappings for incoming hardware interrupts.
To this end, the RCU code considers a pipeline entry as a non-maskable
context alongside in_nmi(), which ends before the companion core is
allowed to reschedule.
On hardware interrupt, the execution flow is as follows:
<IRQ> /* hard irqs off */
core_notify_irq_entry /* disable oob reschedule */
<pipeline_entry>
rcu_nmi_enter
oob_irq_delivery
OR,
inband_irq_logging
rcu_nmi_exit
</pipeline_entry>
core_notify_irq_exit /* re-enable oob reschedule */
synchronize_irq_log
inband_irq_delivery /* hard irqs on */
</IRQ> /* in-band reschedule */As a result, the pipeline core may safely assume that while in a pipeline entry:
-
RCU read sides may be entered to access protected data since RCU is watching,
-
the virtual interrupt state (stall bit) of the in-band stage might legitimately be different from the hardware interrupt state.
This also means that RCU-awareness is denied to activities running on the out-of-band stage outside of the pipeline entry context. As a result, the companion core has no RCU protection against accessing stale data, except from its interrupt handlers (i.e. those marked as running out-of-band with the IRQF_OOB flag).
All of the above is possible because hardware interrupts are always disabled when running the pipeline entry code, therefore pipeline entries are strictly serialized on a given CPU. The following guarantees allow this:
-
out-of-band handlers called from handle_oob_irq() may not re-enable hard interrupts.
-
synchronizing the in-band log with hard interrupts enabled is done outside of the section marked as a pipeline entry.
